NMR Experiments
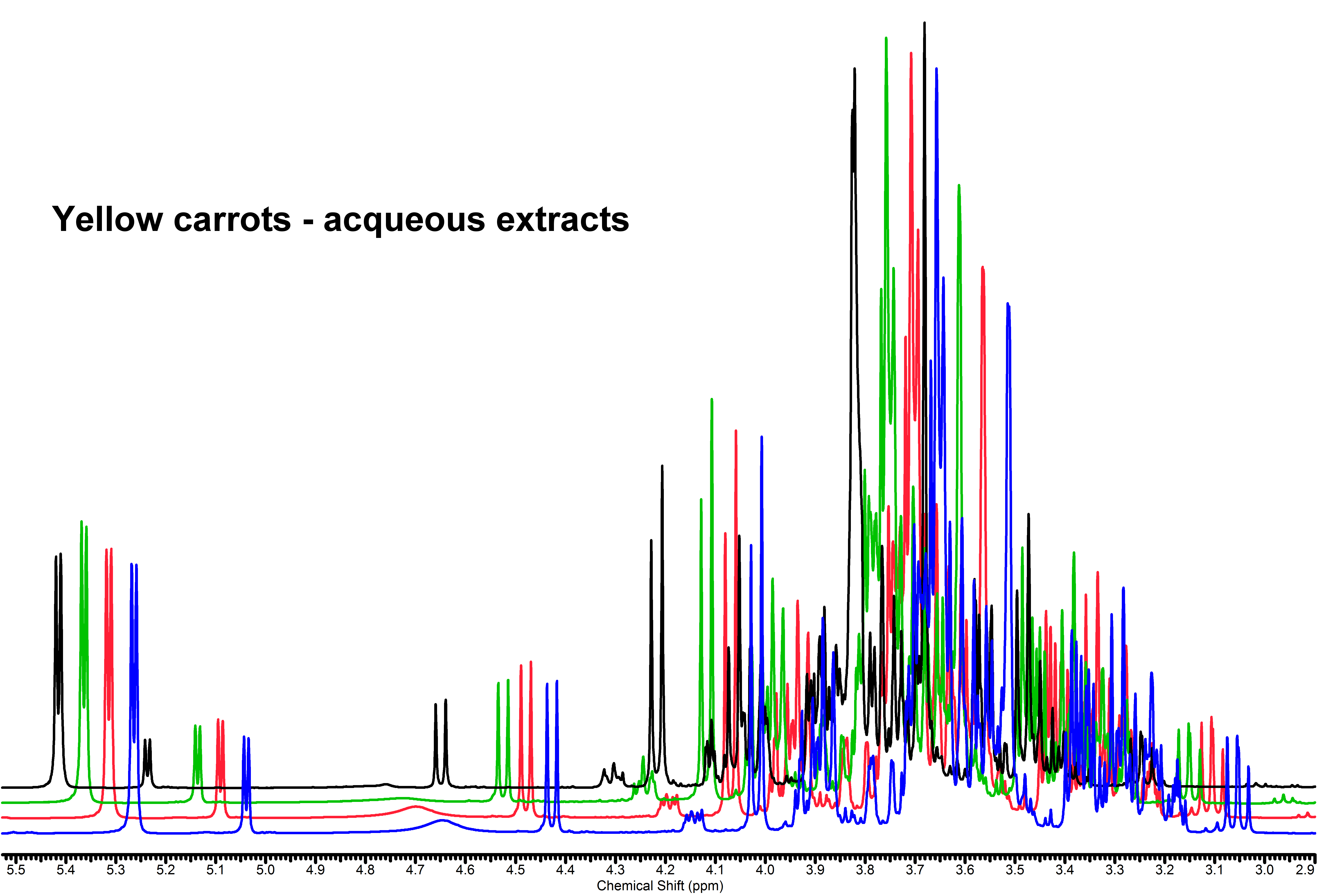 NMR spectra are constituted by a series of resonance signals, each of them originated by the magnetically equivalent nuclei that undergo to the nuclear magnetic resonance experiment (i.e. hydrogen nuclei for 1H NMR spectroscopy). Their position in the spectrum (chemical shift) is peculiar of the chemical group to which the nucleus is bound and of its chemical environment (chemical neighborhood – both directly linked and spatially displaced, stereochemistry), their intensities (areas) are proportional to the concentration of the chemical group, and thence of the molecule. Since any metabolite is composed by more than one chemical group having hydrogen atoms, it comes out that each metabolite is represented by more than one NMR signal – indeed, it usually gives rise to an even more complicated pattern due to spin coupling. The 1H 1D NMR of a mixture produces therefore an overcrowded ensemble of resonance signals, that is a snapshot of all the metabolites contained therein: it is often described as its metabolic fingerprint. Such a situation has some disadvantages and some advantages: many NMR peaks from very similar groups bound to different chemical species can be partially or totally overlapped, and thence difficult to be detected, assigned to a specific metabolite and measured; on the other hand this redundancy can be helpful because each molecule has its own spectral pattern and can be recognized on this basis, and its quantification can be performed anyway by measuring a non-overlapped signal even if the remaining are entangled in intricated regions. Assignment of the overlapping signals can be made much easier by performing 2D NMR experiments, that develop the 1D spectrum complexity into a second dimension.
NMR spectra are constituted by a series of resonance signals, each of them originated by the magnetically equivalent nuclei that undergo to the nuclear magnetic resonance experiment (i.e. hydrogen nuclei for 1H NMR spectroscopy). Their position in the spectrum (chemical shift) is peculiar of the chemical group to which the nucleus is bound and of its chemical environment (chemical neighborhood – both directly linked and spatially displaced, stereochemistry), their intensities (areas) are proportional to the concentration of the chemical group, and thence of the molecule. Since any metabolite is composed by more than one chemical group having hydrogen atoms, it comes out that each metabolite is represented by more than one NMR signal – indeed, it usually gives rise to an even more complicated pattern due to spin coupling. The 1H 1D NMR of a mixture produces therefore an overcrowded ensemble of resonance signals, that is a snapshot of all the metabolites contained therein: it is often described as its metabolic fingerprint. Such a situation has some disadvantages and some advantages: many NMR peaks from very similar groups bound to different chemical species can be partially or totally overlapped, and thence difficult to be detected, assigned to a specific metabolite and measured; on the other hand this redundancy can be helpful because each molecule has its own spectral pattern and can be recognized on this basis, and its quantification can be performed anyway by measuring a non-overlapped signal even if the remaining are entangled in intricated regions. Assignment of the overlapping signals can be made much easier by performing 2D NMR experiments, that develop the 1D spectrum complexity into a second dimension.